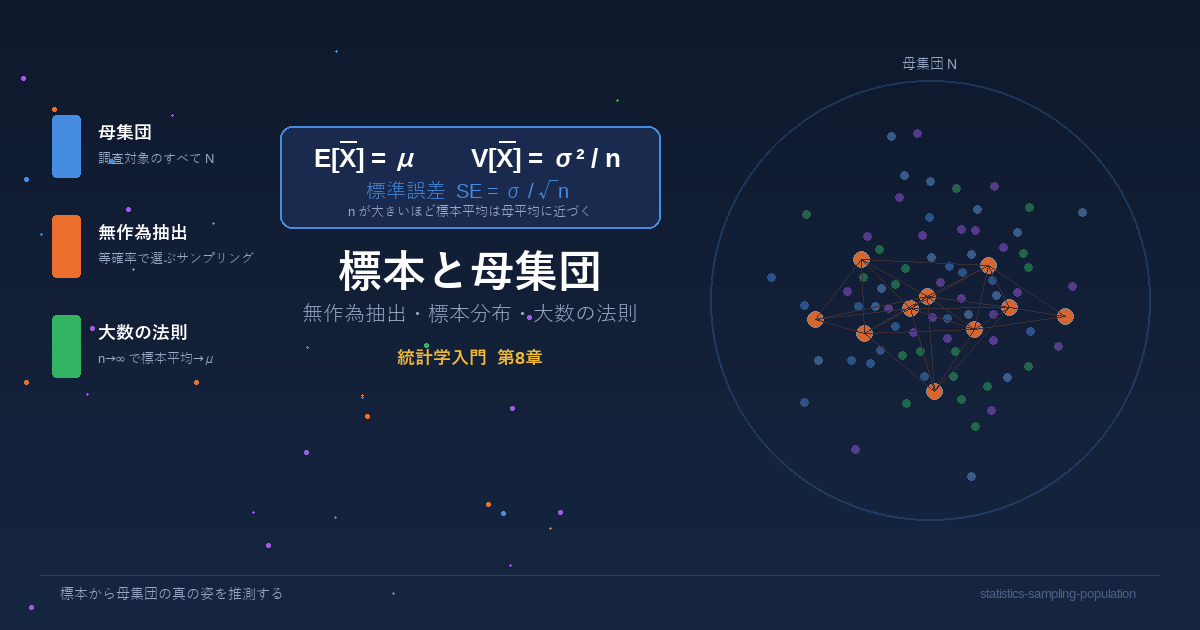
「全国の高校生の学力を調べたい」——でも全員にテストを受けさせるのは現実的ではありません。そこで一部を選び出して調査し、全体を推測するのが 推測統計 の基本的な考え方です。
この章では推測統計の出発点となる 母集団・標本・無作為抽出 の概念を整理し、標本がどのようにばらつくかを表す 標本分布、そして「試行を重ねると真値に近づく」という 大数の法則 まで解説します。
8.1 母集団と標本
母集団(Population) とは、調査・分析したい対象すべての集まりです。一方、母集団から実際に取り出した一部のデータが 標本(Sample) です。
| 用語 | 定義 | 例 |
|---|---|---|
| 母集団 | 分析対象のすべての個体 | 全国の高校生 |
| 標本 | 母集団から選ばれた一部 | 無作為に選ばれた3,000人 |
| 母数(パラメータ) | 母集団の真の値(通常は未知) | 母平均 μ、母分散 σ² |
| 統計量 | 標本から計算した値 | 標本平均 、標本分散 s² |
推測統計のゴールは、標本の統計量から母集団の母数を推測することです。母集団全体を調べることを 全数調査、一部だけ調べることを 標本調査 と呼びます。
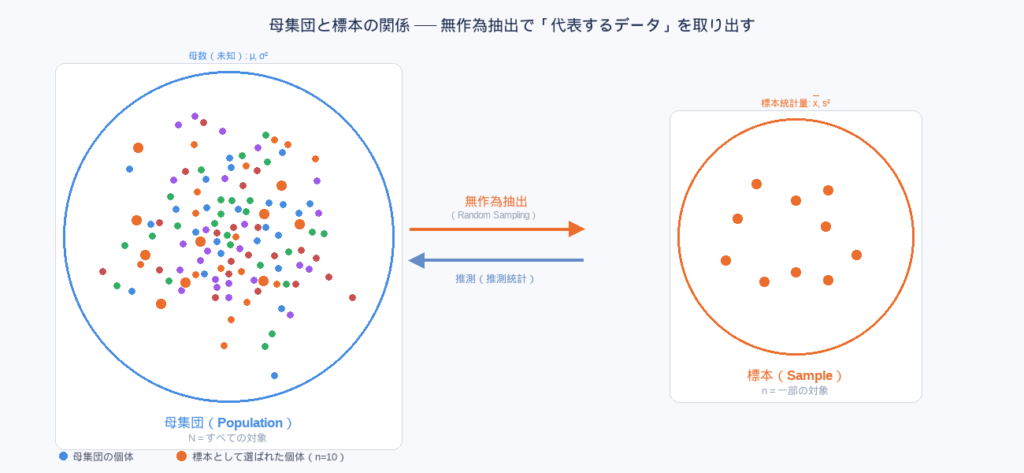
8.2 無作為抽出 — 「偏りのない」サンプリング
無作為抽出(Random Sampling) とは、母集団の各個体が等しい確率で選ばれるようにサンプリングする方法です。特定の傾向を持つ人だけが選ばれてしまう 選択バイアス を防ぐために必須です。
| 手法 | 方法 | 適した場面 |
|---|---|---|
| 単純無作為抽出 | くじ引き・乱数表で完全にランダムに抽出 | 母集団が均質な場合 |
| 系統抽出 | 母集団の個体全てに番号をつけ、一定間隔で抽出(例:10件おきに1件) | リスト化された母集団 |
| 層化抽出 | 母集団をグループ分けして各層から抽出 | 属性(性別・年代)に偏りが出やすい調査 |
| クラスター抽出 | 母集団をグループ分けし、グループをランダムに選択し、選択したグループを全数抽出 | 地域ごとの調査など |
⚠️ 選択バイアスの例:街頭インタビューは昼間に外出している人しか選ばれないため、母集団(全国民)を代表しない可能性があります。
8.3 標本分布と標準誤差
同じ母集団から同じサイズの標本を何度も取る場合を考える。このとき、各回で得られる統計量の分布を標本分布(Sampling Distribution)と言います。下記では、標本平均 の分布について考えます。
標本平均の分布(中心極限定理より):
標準誤差(SE: Standard Error):
n を4倍にすると SE は半分になる
標準誤差 SE は「標本平均がどれくらいばらつくか」の指標です。標本サイズ n が大きいほど SE が小さくなり、標本平均が母平均に近づきます。
| 標本サイズ n | 標準誤差 SE(σ=10 の場合) |
|---|---|
| n = 25 | SE = 10/√25 = 2.0 |
| n = 100 | SE = 10/√100 = 1.0 |
| n = 400 | SE = 10/√400 = 0.5 |
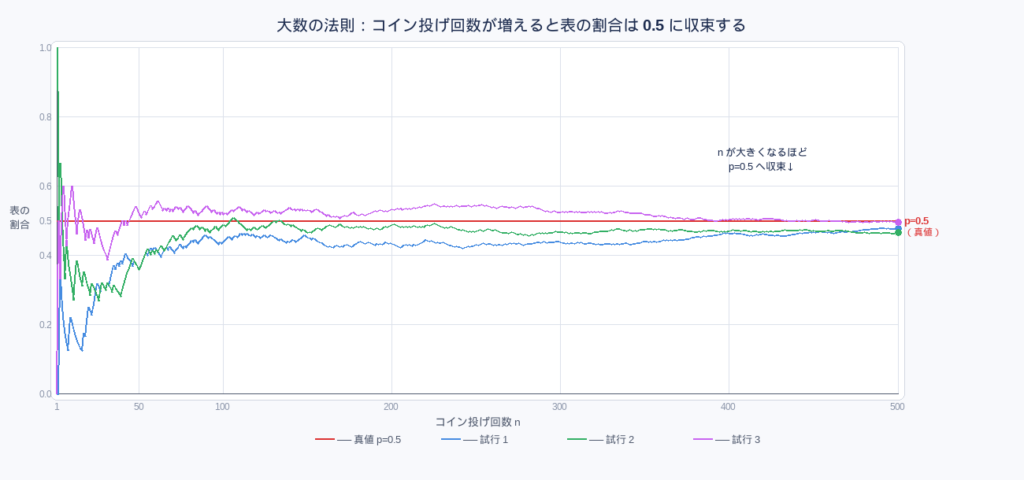
8.4 大数の法則 — 繰り返すほど真実に近づく
大数の法則(Law of Large Numbers) は、「試行回数 n を増やすと、標本平均は母平均 μ に近づいていく」という定理です。
📌 大数の法則:n → ∞ のとき、標本平均X̄ は母平均 μ に確率収束する。
つまり ε > 0 をどんなに小さく取っても、n が十分大きければ |X̄ − μ| < ε となる確率が 1 に近づく。
具体例:コイン投げ
公平なコインを投げ続けると、表が出る割合(標本比率)は徐々に 0.5(= 理論値)に近づいていきます。
大数の法則 と 中心極限定理
| 比較項目 | 大数の法則 | 中心極限定理 |
|---|---|---|
| 内容 | 標本平均が母平均に収束する | 標本平均の分布が正規分布に近づく |
| 焦点 | 値(どこに収束するか) | 形(どんな分布になるか) |
| 活用場面 | 長期的な期待値の見積もり | 区間推定・仮説検定の理論的根拠 |
この章の用語まとめ
| 用語 | 意味 |
|---|---|
| 母集団 | 分析対象となるすべての個体の集まり |
| 標本 | 母集団から実際に取り出したデータの一部 |
| 母数(パラメータ) | 母集団の特性を表す値(μ, σ² など)。通常は未知 |
| 統計量 | 標本から計算した値(x̄, s² など)。母数の推定に使う |
| 無作為抽出 | 各個体が等確率で選ばれるサンプリング方法 |
| 標本分布 | 同サイズの標本を繰り返し抽出したときの統計量の分布 |
| 標準誤差(SE) | 標本平均のばらつきの大きさ。SE = σ/√n |
| 大数の法則 | n → ∞ のとき標本平均が母平均に確率収束する定理 |
次章では、標本から母集団の特性を1つの値で推測する 点推定 を学びます。「良い推定量」の条件(不偏性・一致性・有効性)とその意味を理解していきましょう。

コメント