
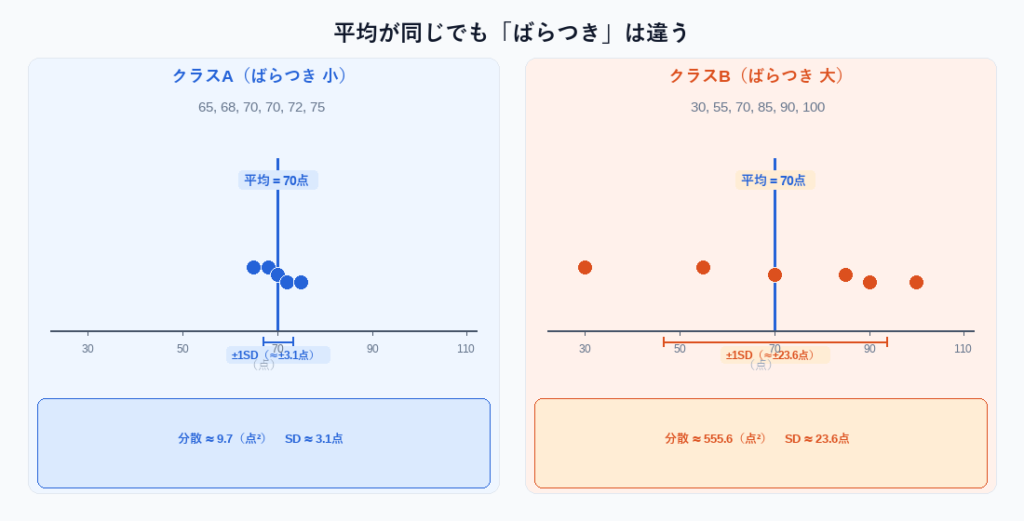
「2つのクラスのテスト平均点は同じ70点——でも、片方は全員が60〜80点に集まり、もう片方は30点台から100点までバラバラ。」
この違いを数値で表すのが、散布度(ばらつきの指標)です。前章で学んだ代表値は「データの中心」を表しますが、散布度は「データの広がり具合」を表します。この章では、最もよく使われる散布度である 分散 と 標準偏差 をステップごとに理解していきましょう。
4.1 ばらつきとは何か
データの「ばらつき」とは、各データが平均からどれくらい離れているかを指します。
次の2つのデータを見てください。どちらも平均は70点ですが、印象がまったく異なります。
クラスA(ばらつき小): 65, 68, 70, 70, 72, 75 → 平均 = 70点
クラスB(ばらつき大): 30, 55, 70, 85, 90, 100 → 平均 = 70点平均だけでは「全員が似たような点数」なのか「得意・不得意がバラバラ」なのかがわかりません。そこで 散布度(ばらつきを表す指標)が必要になります。
4.2 最もシンプルな指標:範囲(Range)
ばらつきを測る最もシンプルな方法は、範囲(レンジ)——最大値と最小値の差——を見ることです。
範囲 = 最大値 − 最小値
クラスA: 75 − 65 = 10点
クラスB: 100 − 30 = 70点クラスBの方がばらつきが大きいことが一目でわかります。しかし範囲には大きな弱点があります。外れ値が1つあるだけで値が大きく変わってしまうのです。
例)クラスBの30点が1人いるだけで範囲が70点になるが、残りの5人は55〜90点に分布(範囲は35点)。外れ値1つが範囲全体を決めてしまう。
そこで登場するのが、すべてのデータを使ってばらつきを計算する指標(分散と標準偏差)です。
4.3 分散への第一歩:偏差(Deviation)
分散を理解するには、まず 偏差 という概念を押さえましょう。偏差とは、各データと平均値の差のことです。
偏差 = 各データの値 − 平均
クラスA(平均=70)の偏差:
65 − 70 = −5
68 − 70 = −2
70 − 70 = 0
70 − 70 = 0
72 − 70 = +2
75 − 70 = +5「偏差の合計を使えばばらつきを測れそう」と思うかもしれませんが、試してみると…
偏差の合計 = (−5) + (−2) + 0 + 0 + (+2) + (+5) = 0偏差の合計は 必ず0になる(プラスとマイナスが打ち消し合う)ため、ばらつきの指標として使えません。この問題を解決するのが分散です。
4.4 分散(Variance)
考え方:偏差を2乗して平均をとる。
偏差のプラス・マイナスを打ち消し合わせないようにするために、偏差を2乗します。2乗すると負の値がなくなり、「平均からの離れ具合」を積み上げることができます。
分散 = 偏差の2乗の平均
= (各偏差²の合計)÷ データ数
クラスA(平均=70)の計算:
偏差²の合計 = (−5)² + (−2)² + 0² + 0² + 2² + 5²
= 25 + 4 + 0 + 0 + 4 + 25
= 58
分散 = 58 ÷ 6 ≈ 9.7(点²)同様にクラスBの分散を計算すると…
クラスB(平均=70)の計算:
偏差²の合計 = (−40)² + (−15)² + 0² + 15² + 20² + 30²
= 1600 + 225 + 0 + 225 + 400 + 900
= 3350
分散 = 3350 ÷ 6 ≈ 558.3(点²)クラスAの分散(≈9.7)に比べてクラスBの分散(≈558)は圧倒的に大きく、ばらつきの大きさを数値で比較できました。
分散の単位問題
ただし、分散の単位は「点²(点の二乗)」になってしまいます。「点²」という単位は直感的にわかりにくいですね。そこで登場するのが標準偏差です。
| クラスA | クラスB | |
|---|---|---|
| 平均 | 70点 | 70点 |
| 分散 | 約 9.7(点²) | 約 558.3(点²) |
4.5 標準偏差(Standard Deviation)
計算方法:分散の平方根をとる
標準偏差は、分散の平方根(√)をとることで、単位を元のデータと同じにした指標です。記号は σ(シグマ) で表します。
標準偏差(σ) = √分散
クラスA: √9.7 ≈ 3.1点
クラスB: √558.3 ≈ 23.6点これで「クラスAのばらつきは±3.1点程度、クラスBは±23.6点程度」と、元のデータと同じ「点」という単位で直感的に表現できます。
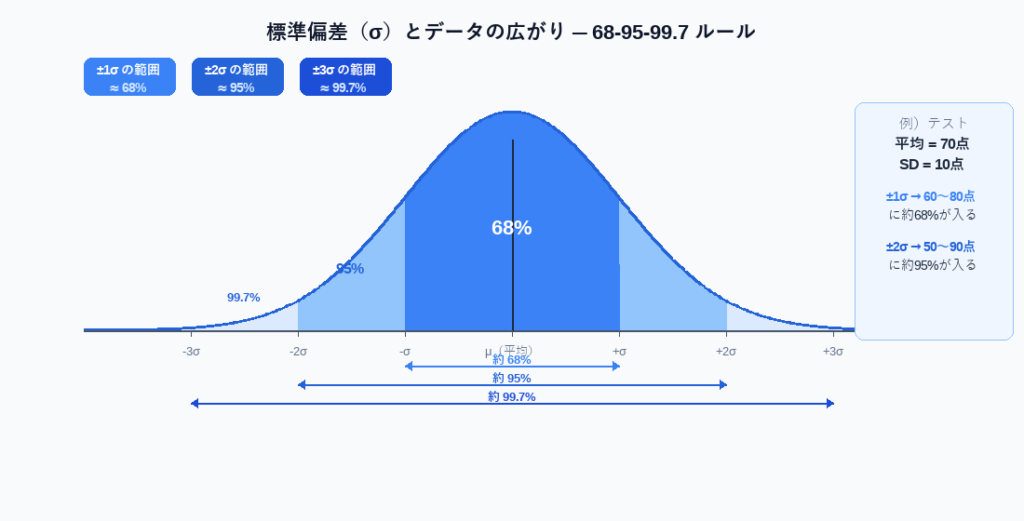
標準偏差の視覚的な意味
データが 正規分布(左右対称の釣り鐘型)に従う場合、標準偏差には次の性質があります。
| 範囲 | データが含まれる割合(目安) |
|---|---|
| 平均 ± 1σ | 約 68% |
| 平均 ± 2σ | 約 95% |
| 平均 ± 3σ | 約 99.7% |
たとえばテストの平均が70点・標準偏差が10点の場合、「約68%の生徒が60〜80点の範囲に入る」と解釈できます。
4.6 母分散と不偏分散:割る数が「n」か「n−1」か
分散を計算するとき、割る数が n(データ数) になるか n−1 になるか、場面によって異なります。これは統計の入門でよく混乱しやすいポイントです。
| 名称 | 割る数 | 使う場面 |
|---|---|---|
| 母分散(σ²) | n | 手元のデータ全体が「母集団」そのものである場合(クラス全員の点数など) |
| 不偏分散(s²) | n − 1 | 手元のデータが「母集団の一部(標本)」である場合(世論調査、実験データなど) |
不偏分散で n−1 を使う理由は、不偏性(不偏分散の期待値が母分散と等しくなるように補正するため)ですが、入門段階では「標本データを使うときは n−1 で割る」と覚えておきましょう。ExcelやPythonでも n−1 を使う関数(STDEV、np.std のデフォルト ddof=1)が多く使われています。
覚え方の目安:クラス全員・調査対象全員のデータがある → n で割る(母分散)/一部を抽出したデータ → n−1 で割る(不偏分散)
4.7 単位が違うデータを比べる:変動係数(CV)
標準偏差は単位を持つため、単位や規模が違うデータを比較するのには向きません。
例えば「身長(cm)の標準偏差 5cm」と「体重(kg)の標準偏差 5kg」、どちらのばらつきが相対的に大きいかは標準偏差の値だけではわかりません。そこで使われるのが 変動係数(Coefficient of Variation: CV)です。
変動係数(CV) = 標準偏差 ÷ 平均 × 100(%)
例)
身長: 平均 170cm、標準偏差 5cm → CV = 5÷170×100 ≈ 2.9%
体重: 平均 65kg、 標準偏差 5kg → CV = 5÷65×100 ≈ 7.7%
→ 体重の方が相対的なばらつきが大きい変動係数はパーセント(%)で表されるため、単位や平均値が異なるデータ間でもばらつきを公平に比較できます。
4.8 散布度の使い分けまとめ
| 指標 | 計算方法 | 強み | 弱み |
|---|---|---|---|
| 範囲(Range) | 最大値 − 最小値 | 計算が簡単、直感的 | 外れ値に弱い |
| 分散(Variance) | 偏差²の平均 | 全データを使う、数学的に扱いやすい | 単位が元データの二乗 |
| 標準偏差(SD) | √分散 | 元データと同じ単位、最もよく使われる | 外れ値に影響される |
| 変動係数(CV) | SD ÷ 平均 × 100 | 単位・規模が違うデータを比較できる | 平均が0に近いと使えない |
判断フロー
ばらつきを測りたい
├─ とにかく簡単に確認したい → 範囲
├─ 精度よく測りたい
│ ├─ 同じ単位・規模のデータ同士を比べる → 標準偏差
│ └─ 単位や規模が異なるデータを比べる → 変動係数(CV)
└─ 数式で扱いたい(回帰など高度な分析) → 分散まとめ
- 散布度はデータの「広がり具合」を表す指標。代表値(平均など)だけでは見えないばらつきを捉える。
- 範囲(最大値−最小値)は最もシンプルだが外れ値の影響を受けやすい。
- 分散は偏差の2乗を平均したもの。単位が元データの二乗になる点に注意。
- 標準偏差は分散の平方根。元データと同じ単位で、最も広く使われる散布度。
- 標本データには n−1 で割る不偏分散を使う。
- 変動係数(CV)を使うと、単位が異なるデータのばらつきを公平に比較できる。
次章では、代表値とばらつきを組み合わせて分布全体の形を捉える方法——ヒストグラムと箱ひげ図——を学びます。データを「可視化」することで、数値だけではわからなかった情報が一気に見えてきます。
この章の用語まとめ
| 用語(日) | 用語(英) | 意味 |
|---|---|---|
| 散布度 | Measure of dispersion | データのばらつきを数値で表す指標の総称 |
| 範囲 | Range | 最大値と最小値の差 |
| 偏差 | Deviation | 各データと平均の差 |
| 分散 | Variance | 偏差の2乗を平均したもの(単位:元データの2乗) |
| 標準偏差 | Standard Deviation (SD) | 分散の平方根。元データと同じ単位のばらつき指標 |
| 母分散 | Population variance (σ²) | 母集団全体のデータで計算する分散(÷n) |
| 不偏分散 | Unbiased variance (s²) | 標本データから母分散を推定する分散(÷(n−1)) |
| 変動係数 | Coefficient of Variation (CV) | 標準偏差を平均で割った無次元のばらつき指標(%) |
| 正規分布 | Normal distribution | 平均を中心に左右対称の釣り鐘型をした分布 |
コメント