
対象レベル:ゼロから学ぶ入門者 | 所要時間:約15分
📌 この章で学ぶこと
- データが「質的」か「量的」かを見分けられる
- 連続変数と離散変数の違いを説明できる
- 4つの尺度水準を理解し、どのデータに何の分析が使えるかを把握する
前章のおさらい:統計学には「記述統計」と「推測統計」の2種類があります。どちらの分析を使うにしても、最初にやるべきことが1つあります——それが「手元のデータの種類を正しく把握すること」です。
1. なぜデータの種類を見分ける必要があるのか?
こんな失敗事例を想像してみてください。
❌ よくある失敗例
アンケートで「満足度を1〜5で答えてください」と聞いた。
→ 集まったデータ:1, 3, 5, 2, 4, 5, 3 …
→ 「平均は3.3点です!」と報告した。
⚠️ これは正しい分析でしょうか?
実は「1〜5の満足度」は等間隔とは限りません。「3」が「1」の3倍の満足度を意味するわけではありません。このデータに平均を使うのは、場合によって不適切です。
アンケートで「満足度を1〜5で答えてください」と聞いた。
→ 集まったデータ:1, 3, 5, 2, 4, 5, 3 …
→ 「平均は3.3点です!」と報告した。
⚠️ これは正しい分析でしょうか?
実は「1〜5の満足度」は等間隔とは限りません。「3」が「1」の3倍の満足度を意味するわけではありません。このデータに平均を使うのは、場合によって不適切です。
データの種類を間違えると、使ってはいけない分析手法を使ってしまい、誤った結論を引き出してしまいます。データ分析の第一歩は、必ず「このデータは何の種類か?」を確認することから始まります。
2. データの2大分類:質的データと量的データ
すべてのデータはまず「質的データ」か「量的データ」に分類されます。
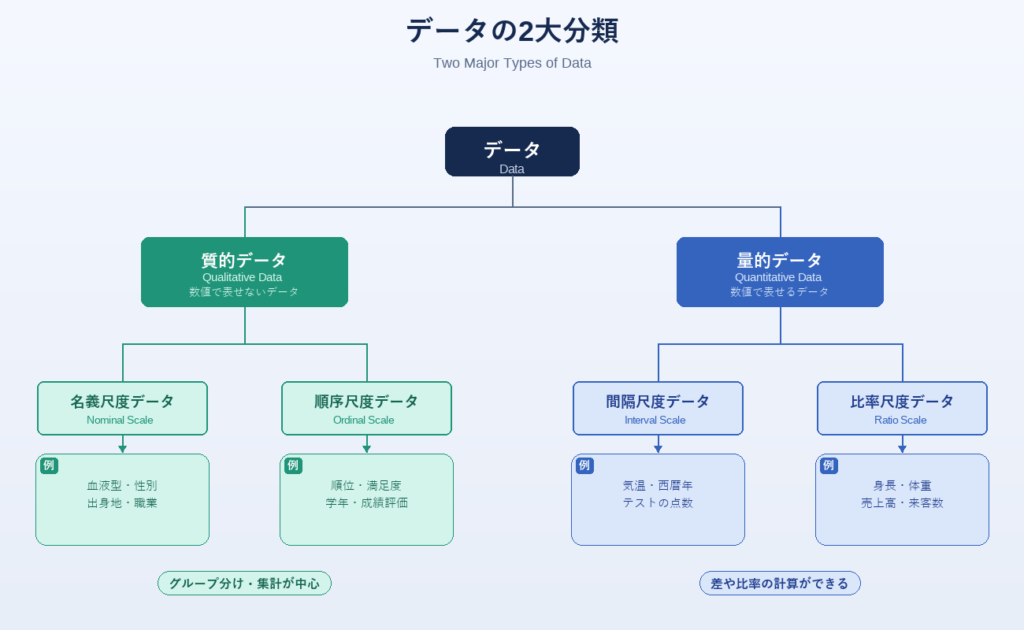
🏷️ 質的データ(Qualitative Data / Categorical Data)
分類やグループを表すデータです。数字で表現されることもありますが、その数字に「大きさ」や「差」の意味はありません。
身近な例
・血液型(A / B / O / AB)
・性別(男性 / 女性 / その他)
・出身都道府県、職業、好きな食べ物
・アンケートの満足度(1:不満 〜 5:満足)
・学生証番号 012345(数字だが「大きさ」に意味なし)
・血液型(A / B / O / AB)
・性別(男性 / 女性 / その他)
・出身都道府県、職業、好きな食べ物
・アンケートの満足度(1:不満 〜 5:満足)
・学生証番号 012345(数字だが「大きさ」に意味なし)
「血液型 A は血液型 B の半分」——これは意味をなしません。質的データには平均を計算することはできず、代わりに最頻値や割合(%)で表します。
📐 量的データ(Quantitative Data)
数値として表され、大小の比較や四則演算(足し算・引き算・掛け算・割り算)が意味をもつデータです。
身近な例
・身長 172.5 cm、体重 68 kg
・今日の最高気温 34.2℃
・テストの点数 85点
・月の残業時間 42時間
・商品の売上金額 128,000円
・身長 172.5 cm、体重 68 kg
・今日の最高気温 34.2℃
・テストの点数 85点
・月の残業時間 42時間
・商品の売上金額 128,000円
「172 cm の人は 86 cm の人の2倍の身長がある」——このような比較が意味をもちます。平均・分散・標準偏差などの計算も問題なく使えます。
| 比較項目 | 質的データ | 量的データ |
|---|---|---|
| 別名 | カテゴリデータ | 数値データ |
| 四則演算 | ❌ できない(基本的に) | ✅ できる |
| 代表値 | 最頻値・割合 | 平均・中央値 |
| 例 | 血液型・職業・満足度評価 | 身長・体重・点数・気温 |
3. 量的データのさらなる分類:連続変数と離散変数
量的データはさらに2つに分かれます。
連続変数(Continuous Variable)
理論上、どんな値でも取りうるデータです。小数点以下がいくらでも続く可能性があります。
身長:172.534… cm | 気温:23.8℃ | 時間:2.5時間
体重:68.21 kg | 距離:3.14 km | 濃度:0.05 mg/L
体重:68.21 kg | 距離:3.14 km | 濃度:0.05 mg/L
離散変数(Discrete Variable)
とびとびの値(整数)しか取らないデータです。「1.5人の子供」は存在しません。
サイコロの目:1, 2, 3, 4, 5, 6 | 来客数:0, 1, 2, 3 …人
家族の人数:1, 2, 3 …人 | 正解した問題数:0〜10問
家族の人数:1, 2, 3 …人 | 正解した問題数:0〜10問
💡 使い分けのポイント
「0と1の間に値が存在するか?」と考えてみましょう。
身長は 170 cm と 171 cm の間に 170.5 cm が存在する → 連続変数
来客数は 2人と 3人の間に 2.5人は存在しない → 離散変数
「0と1の間に値が存在するか?」と考えてみましょう。
身長は 170 cm と 171 cm の間に 170.5 cm が存在する → 連続変数
来客数は 2人と 3人の間に 2.5人は存在しない → 離散変数
4. 尺度水準
統計学では、データをさらに細かく4つの「尺度水準」に分類します。水準が上がるほど使える統計手法の幅が広がります。
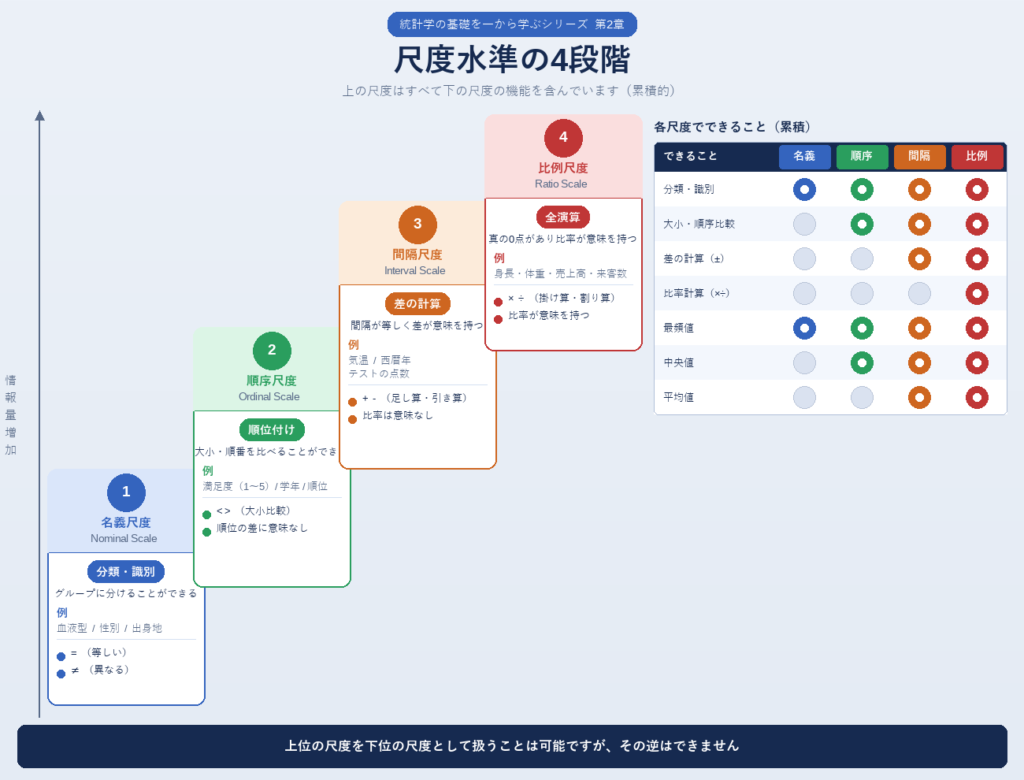
① 名義尺度(Nominal Scale)
単なる「分類ラベル」です。数字を使っても大小・順序の意味はありません。
例:血液型(A=1, B=2, O=3, AB=4)、性別、都道府県番号、選手の背番号
できること:分類・集計・最頻値
できること:分類・集計・最頻値
② 順序尺度(Ordinal Scale)
順位や大小はあるが、間隔が等しいとは言えません。
例:満足度(1〜5)、学年(1〜6年生)、マラソンの順位(1位・2位・3位)
⚠️ 「1位と2位の差」=「2位と3位の差」とは限らない
できること:分類・順位比較・中央値
⚠️ 「1位と2位の差」=「2位と3位の差」とは限らない
できること:分類・順位比較・中央値
③ 間隔尺度(Interval Scale)
差(間隔)に意味がある。ただし「ゼロが絶対的」ではない。
例:気温(℃)、西暦年、IQスコア
「20℃と30℃の差 = 30℃と40℃の差(どちらも10℃)」→ 差は意味あり ✅
「20℃は10℃の2倍暖かい」→ 意味なし ❌(0℃は「熱さがゼロ」ではない)
できること:分類・順位・平均・標準偏差
「20℃と30℃の差 = 30℃と40℃の差(どちらも10℃)」→ 差は意味あり ✅
「20℃は10℃の2倍暖かい」→ 意味なし ❌(0℃は「熱さがゼロ」ではない)
できること:分類・順位・平均・標準偏差
④ 比例尺度(Ratio Scale)
差にも比率にも意味がある。絶対的なゼロが存在する。
例:身長・体重・収入・時間・距離・個数
「身長 180 cm は 90 cm の2倍」→ 意味あり ✅
「体重 0 kg = 完全に体重がない」→ 絶対的なゼロ ✅
できること:すべての統計手法が使える
「身長 180 cm は 90 cm の2倍」→ 意味あり ✅
「体重 0 kg = 完全に体重がない」→ 絶対的なゼロ ✅
できること:すべての統計手法が使える
| 尺度 | 分類 | 順序 | 等間隔 | 絶対ゼロ | 例 |
|---|---|---|---|---|---|
| 名義尺度 | ✅ | ❌ | ❌ | ❌ | 血液型・性別 |
| 順序尺度 | ✅ | ✅ | ❌ | ❌ | 満足度・順位 |
| 間隔尺度 | ✅ | ✅ | ✅ | ❌ | 気温・西暦 |
| 比例尺度 | ✅ | ✅ | ✅ | ✅ | 身長・体重・収入 |
📌 尺度水準と質的・量的データの対応
・名義尺度・順序尺度 → 質的データ
・間隔尺度・比例尺度 → 量的データ
尺度水準が高いほど使える統計手法の幅が広がります。ただし、
高い尺度のデータを低い尺度として扱うことは可能ですが、逆はできません。
・名義尺度・順序尺度 → 質的データ
・間隔尺度・比例尺度 → 量的データ
尺度水準が高いほど使える統計手法の幅が広がります。ただし、
高い尺度のデータを低い尺度として扱うことは可能ですが、逆はできません。
📝 章末練習問題
Q1. 次のデータを「量的データ」か「質的データ」に分類し、さらに尺度水準(名義・順序・間隔・比例)を答えよ。
(a)スマートフォンの機種名(iPhone / Galaxy / Pixel …)
(b)100m 走のタイム(秒)
(c)映画の星評価(★1〜★5)
(d)今日の最低気温(℃)
(e)1日に飲んだコーヒーの杯数
(a)スマートフォンの機種名(iPhone / Galaxy / Pixel …)
(b)100m 走のタイム(秒)
(c)映画の星評価(★1〜★5)
(d)今日の最低気温(℃)
(e)1日に飲んだコーヒーの杯数
Q2. 社員100人に「通勤時間(分)」と「通勤手段(電車・バス・車・徒歩)」を調査した。
それぞれのデータに使える代表値(平均・中央値・最頻値)を選び、理由を述べよ。
それぞれのデータに使える代表値(平均・中央値・最頻値)を選び、理由を述べよ。
Q3. 「気温20℃は10℃の2倍暑い」という表現が統計的に正しくない理由を、尺度水準の観点から説明せよ。
▶ Q1の解答を見る
(a)機種名 → 質的データ・名義尺度(分類のみ。大小なし)
(b)100m走タイム → 量的データ・比例尺度(絶対ゼロあり。10秒は5秒の2倍の時間)
(c)星評価 → 質的データ・順序尺度(★3>★2だが、差が等間隔とは言えない)
(d)最低気温 → 量的データ・間隔尺度(差は意味あり。ただし0℃は「熱さゼロ」ではない)
(e)コーヒーの杯数 → 量的データ・比例尺度かつ離散変数(整数値のみ。0杯は「完全にゼロ」)
(b)100m走タイム → 量的データ・比例尺度(絶対ゼロあり。10秒は5秒の2倍の時間)
(c)星評価 → 質的データ・順序尺度(★3>★2だが、差が等間隔とは言えない)
(d)最低気温 → 量的データ・間隔尺度(差は意味あり。ただし0℃は「熱さゼロ」ではない)
(e)コーヒーの杯数 → 量的データ・比例尺度かつ離散変数(整数値のみ。0杯は「完全にゼロ」)
✅ この章のまとめ
- データはまず質的データ(カテゴリ)と量的データ(数値)に分類される
- 量的データはさらに連続変数(どんな値もとれる)と離散変数(とびとびの値)に分かれる
- 尺度水準は低い順に名義→順序→間隔→比例の4段階。水準が高いほど使える分析が増える
- 名義・順序は質的データ、間隔・比例は量的データに対応する
- データの種類を誤ると、使えない統計手法を使って誤った結論を出すリスクがある
➡️ 次の章へ
第3章:平均・中央値・最頻値 — データを「1つの数」で表す
データの種類が分かったら、次はそのデータを要約することを学びます。
「このクラスの成績を一言で表すと?」という問いに答えるのが代表値です。
平均・中央値・最頻値の使い分けを、外れ値のある年収データなどの身近な例で徹底解説します。
データの種類が分かったら、次はそのデータを要約することを学びます。
「このクラスの成績を一言で表すと?」という問いに答えるのが代表値です。
平均・中央値・最頻値の使い分けを、外れ値のある年収データなどの身近な例で徹底解説します。
引き続き一緒に学んでいきましょう。
コメント