
前章では、標本から1つの数値でパラメータを推測する「点推定」を学びました。しかし点推定には致命的な弱点があります——「どのくらいズレうるか」という精度情報がないことです。
そこで登場するのが 区間推定(Interval Estimation) です。「母平均は 48〜56 点の間にある可能性が高い」のように、幅を持たせて推測し、その信頼性を確率で示す手法です。
この章では、区間推定の仕組み、95%信頼区間の正しい解釈(よくある誤解も解説)、z分布・t分布の使い分け、そして具体的な計算例を図解つきで学びます。
10.1 区間推定とは
区間推定では、「母数がこの区間に入りそうだ」という 信頼区間(Confidence Interval, CI) を推定します。
| 項目 | 内容 |
|---|---|
| 信頼区間 | 母数を含むと期待される区間(例:[48.2, 55.8]) |
| 信頼係数 | 区間が母数を含む確率(例:95%)。1−αで表す |
| 有意水準 α | 区間が母数を含まない確率(例:5%) |
信頼係数は 95%(α=0.05) が最も多く使われますが、場面によって90%や99%も使われます。
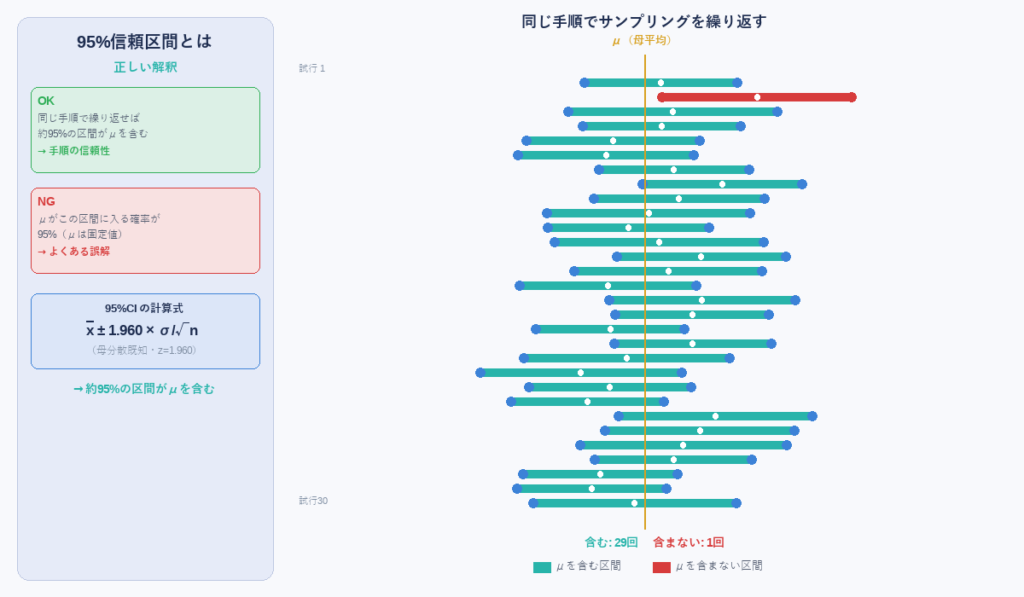
95%信頼区間の「正しい解釈」と「よくある誤解」
ここは非常に誤解されやすいポイントです。まず結論から言いましょう。
| 正誤 | 解釈 |
|---|---|
| ✅ 正 | 「同じ手順でサンプリングを十分多く繰り返せば、約95%の信頼区間がμを含む」 |
| ❌ 誤 | 「μがこの区間に入る確率が95%」 |
母平均μは固定された定数です。区間を構築するたびに「区間の側が変わる」のであって、μが動くわけではありません。信頼係数95%とは、「この手順の信頼性が95%」を意味します。
10.2 母分散既知の場合
母分散σ²が既知の場合を考えます。標本平均 は正規分布に従います。
従って、母平均μの 信頼水準 (1−α)×100% の信頼区間は次の式で求まります。
| 信頼水準 | zα/2(両側) | 計算式 |
|---|---|---|
| 90% | 1.645 | |
| 95% | 1.960 | |
| 99% | 2.576 |
標本平均は95%の確率で下記図の青色の区間の値をとる。このとき、95%信頼区間は母平均μを含む。一方、赤色の区間に平均が入る場合は、95%信頼区間はμを含まない。
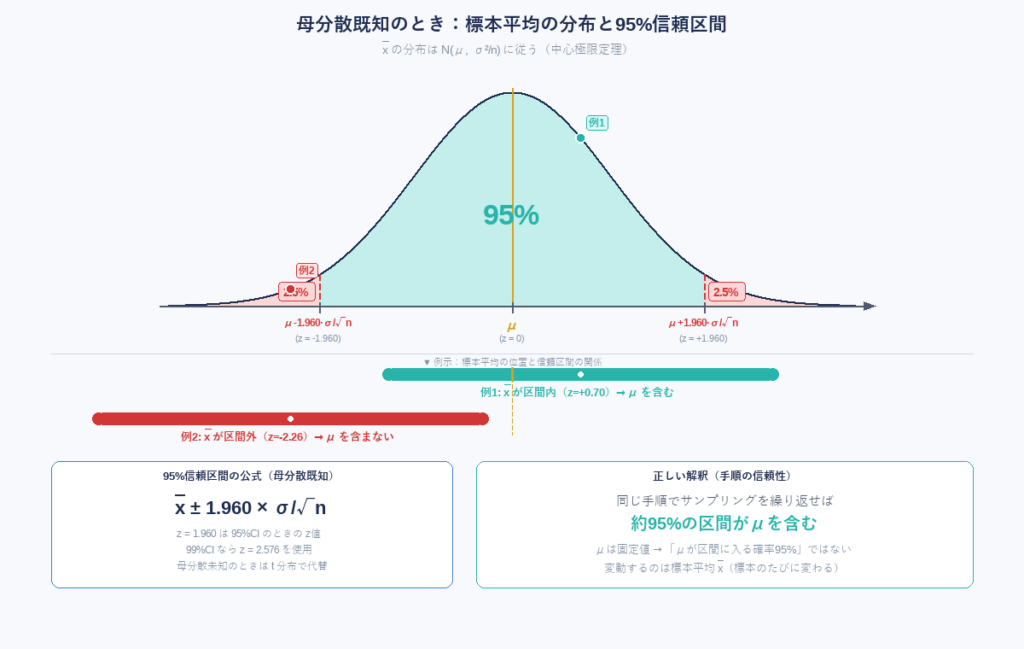
例題①:z分布を使った95%信頼区間の計算
あるテストの母標準偏差が σ=10 点、n=25人の標本を取ったところ だったとします。母平均μの95%信頼区間を求めてください。
| ステップ | 計算 |
|---|---|
| 標準誤差 SE | |
| 95%誤差 | |
| 信頼区間 | [70 − 3.92, 70 + 3.92] = [66.08, 73.92] |
この手順を繰り返せば、約95%の区間ではμが信頼区間に含まれます。
10.3 母分散未知の場合(t分布)
実際の分析では母分散σ²は 未知 であることがほとんどです。このとき、σを標本標準偏差 s で代替すると、統計量は t分布 に従います。
| 条件 | 統計量 | 分布 |
|---|---|---|
| 母分散 既知 | 標準正規分布 N(0,1) | |
| 母分散 未知 | t(n−1)分布(自由度 n−1) |
t分布はz分布よりも 裾が厚く(重く) なります。つまり同じ信頼水準でも、t分布を使った信頼区間の方が広くなります。これは「σを推定する不確実性の分だけ、区間を広げて対応する」という考え方です。
自由度dfが大きくなるほど(標本が増えるほど)、t分布は標準正規分布に近づきます。
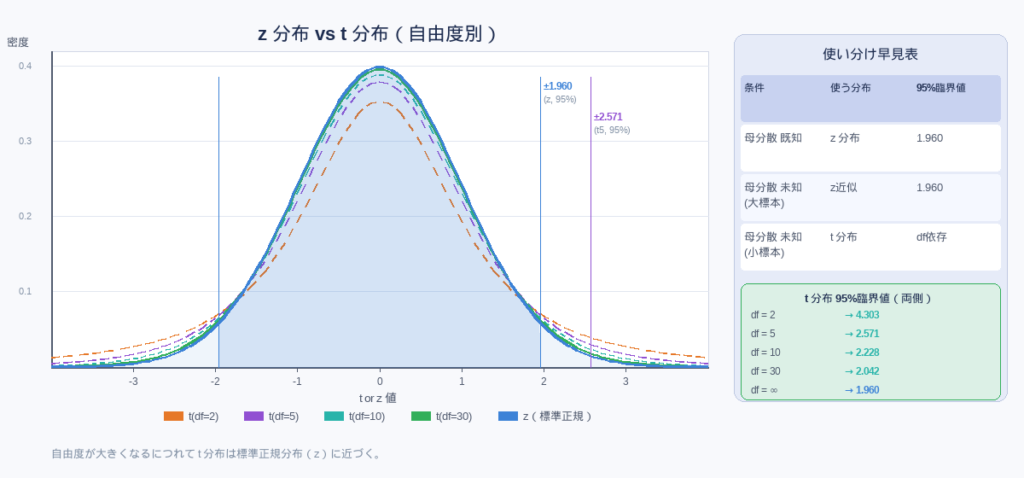
t分布を使った信頼区間の式
| 信頼水準 | 自由度 | 計算式 |
|---|---|---|
| 95% | df=5 | |
| df=10 | ||
| df=30 |
例題②:t分布を使った95%信頼区間の計算
あるサプリメントの効果測定として、n=16名で血圧変化を測定。標本平均 、標本標準偏差 s=4.0 でした。母平均μの95%信頼区間を求めてください(母分散未知)。
| ステップ | 計算 |
|---|---|
| 自由度 | df = n−1 = 16−1 = 15 |
| t臨界値 | t0.025(15) = 2.131 |
| 標準誤差 SE | |
| 95%誤差 E | E = 2.131 × 1.0 = 2.131 |
| 信頼区間 | [−8.5 − 2.131, −8.5 + 2.131] = [−10.63, −6.37] |
95%信頼区間がすべて負の範囲にあるなので、「サプリメントは血圧を下げる効果がある」と95%の信頼水準で言えます。
10.4 信頼区間の幅と標本サイズ
信頼区間の幅(精度)は以下の要因に影響されます。
| 要因 | 幅への影響 | 理由 |
|---|---|---|
| 標本サイズ n ↑ | 幅が 狭くなる | SE = σ/√n なので n が大きいほど SE が小さい |
| 信頼係数 ↑ | 幅が 広くなる | 99%にすると z=2.576 で、より広い範囲が必要 |
| σ(ばらつき)↑ | 幅が 広くなる | データのばらつきが大きいほど推定が不確か |
「精度を上げたいなら標本サイズを増やす」——これが区間推定の基本的な対策です。信頼水準を下げるという選択肢もありますが、その分「外れる確率」が上がります。精度と信頼性のトレードオフを意識しましょう。
第10章のまとめ
| ポイント | 内容 |
|---|---|
| 区間推定 | 母数を含む「範囲」を確率付きで示す推定法 |
| 信頼区間の正しい解釈 | 「同じ手順で信頼区間を推定した際に95%の区間はμを含む」 → 手順の信頼性 |
| 母分散既知 | z分布を使用。95%CI: x̄ ± 1.960 × σ/√n |
| 母分散未知 | t分布を使用(自由度 df=n−1)。t分布はzより裾が厚い |
| 精度を上げるには | 標本サイズ n を増やす(SE = σ/√n が小さくなる) |
次章では、区間推定をもとにした「仮説検定」に進みます。「帰無仮説は棄却できるか」という判断プロセスを学びましょう。
← 前の章:第9章 点推定 | 次の章:第11章 仮説検定 →

コメント